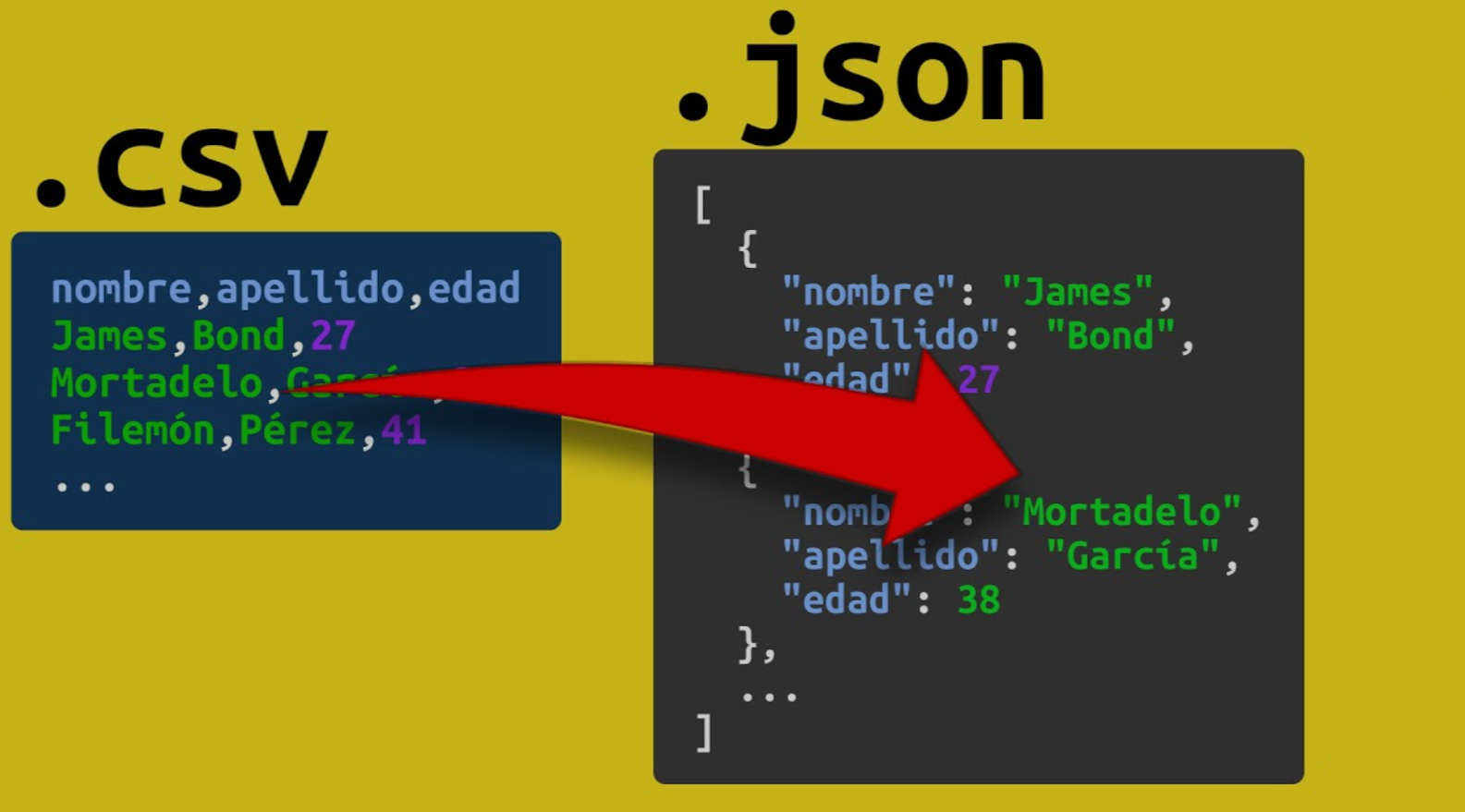
Introducción
Miller es una herramienta de línea de comandos de código abierto para realizar consultas, limpiar, manipular y transformar datos entre diferentes formatos de archivo como CSV, TSV y JSON.
En el mundo de los datos, el formato CSV lo encontraremos en casi cualquier proyecto en el que participemos y es fundamental poder contar con herramientas que nos permitan manipular este formato.
Existen librerías como Pandas o Polars para hacer estas manipulaciones y conversiones, pero es necesario saber programación y conocer su documentación para poder usarlas.
Miller es una herramienta que se usa a través de la línea de comandos, siguiendo la tradición de otras grandes herramientas del mundo Linux, como sed o awk, aunque se puede usar en Windows también.
Miller soporta los siguientes formatos:
- CSV (formato separado por comas)
- TSV (formato separado por tabuladores)
- JSON (JavaScript Object Notation)
- Líneas JSON (JSON un registro por línea, no contenido en […])
- PPRINT (formato tabular formateado)
- XTAB (formato vertical tabular formateado)
- NIDX* (formato numéricamente indexado, sin etiquetas y con etiquetas implícitas “1”, “2”, etc.)
- DKVP* (formato delimitado con pares clave valor)
Si no tienes ganas de usar la línea de comandos, puedes seguir buscando algún conversor online pero si inviertes unos minutos en seguir leyendo, quizás te valga la pena, ya que como he comentado, Miller no sólo permite hacer una conversión de CSV a JSON sino manipulaciones complejas sobre los datos, como por ejemplo, filtrar datos o realizar transformaciones sobre una columna.
1. Instalación de Miller (mlr)
Para instalar Miller en Windows, podemos usar la herramienta choco para instalar el binario de la siguiente forma:
choco install miller
De todas maneras, para este tipo de herramientas, te recomiendo su instalación dentro del entorno WSL de Windows para evitar instalaciones complejas sobre Windows.
En Linux, si usamos Ubuntu o Debian podemos instalar la herramienta usando el siguiente comando:
apt-get install miller
Si tienes otra distribución consulta la documentación del proyecto ya que la herramienta esta soportada en multitud de distribuciones Linux y OSX.
El comando para usar Miller es mlr. Podemos comprobar que la instalación es correcta ejecutando el comando mlr con el siguiente parámetro:
mlr --version

2. Probando la herramienta antes de la conversión
Para probar la herramienta y realizar la conversión de un CSV a JSON vamos a utilizar un CSV de ejemplo llamado customers-100.csv que he descargado de Datablist. Este dataset contiene 100 registros, cantidad mas que suficiente para trastear con la herramienta.
Antes de realizar la conversión de CSV a JSON vamos a realizar algunas pruebas.
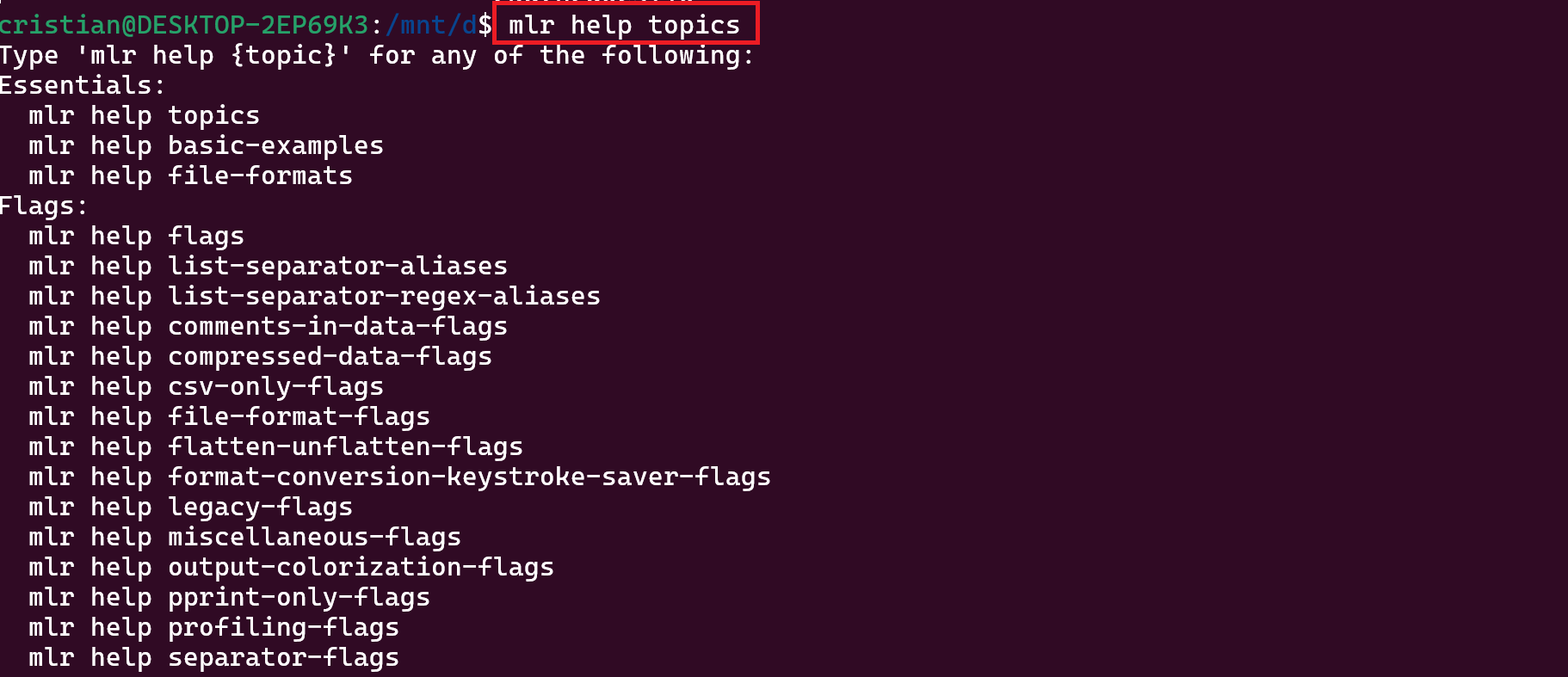
Miller nos permite obtener ayuda extendida sobre todo lo que es capaz de hacer ejecutando el comando mlr con los siguientes parámetros:
mlr help topics
La salida del comando nos muestra ayuda ampliada de todas las opciones de la herramienta:
2.1 Visualización del contenido del archivo CSV
Como paso previo a cualquier tipo de manipulación de los datos, es útil ver por pantalla el contenido del archivo CSV y ver como lo procesa Miller.
Podemos usar el siguiente comando par ver el contenido del archivo:
mlr --icsv --opprint cat customers-100.csv

También si queremos visualizar el contenido ordenado por alguna columna en concreto podemos hacerlo.
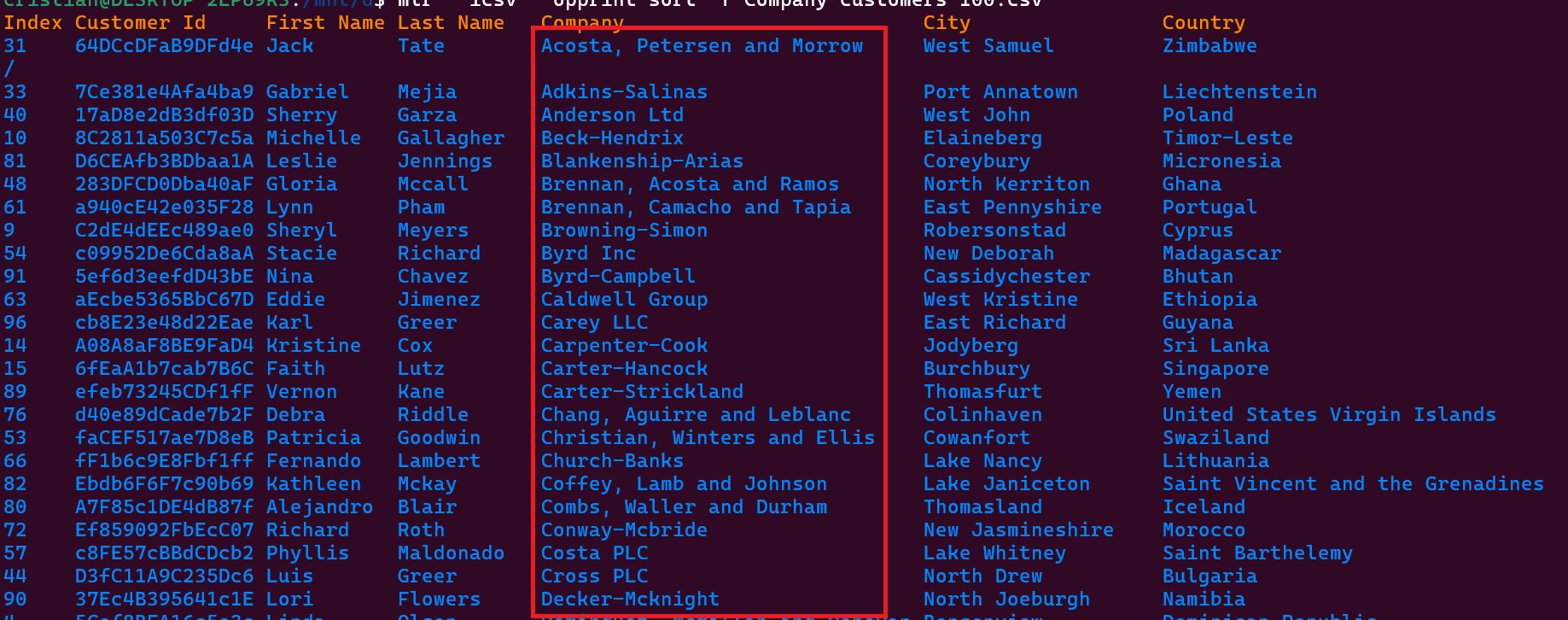
Para obtener la visualización del contenido del CSV ordenado por el nombre de la “Company” podemos ejecutar el comando con los siguientes parámetros:
mlr --icsv --opprint sort -f Company customers-100.csv
También al más puro estilo Pandas podemos listar los 4 primeros registros usando los siguientes parámetros:
mlr --csv --opprint head -n 4 customers-100.csv

2.4 Mostrar únicamente columnas concretas
Si tenemos un archivo muy grande puedo interesarnos mostrar el contenido de una columna concreta y obviar el resto.
Miller ofrece muchas opciones para realizar esta tarea, incluyendo filtrados condicionales.
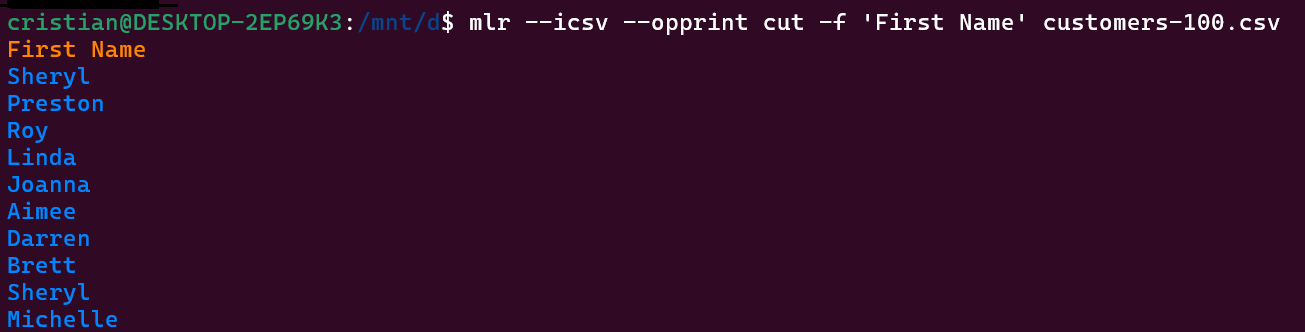
Vamos a ver un ejemplo, supongamos que sólo queremos obtener los datos de la columna “First Name”.
Para lograrlo podemos ejecutar el comando con el siguiente parámetros:
mlr --icsv --opprint cut -f 'First Name' customers-100.csv
De la misma forma, podemos excluir todas aquellas columnas que no queramos.
Si nos interesa mostrar el contenido de todas las columnas excluyendo “First Name”, ejecutamos el comando con los siguientes parámetros:
mlr --icsv --opprint cut -f 'First Name' customers-100.csv

2.3 Filtrar por el contenido de una columna
Una función muy útil es poder filtrar rápidamente por el contenido de una columna en concreto. Usando Miller podemos aplicar un criterio de búsqueda después del parámetro filter:
mlr --csv --opprint filter '$Country == "United Arab Emirates"' customers-100.csv

Como podemos ver aplicando filter ‘$Country == “United Arab Emirates”’ le decimos a la herramienta que queremos todos aquellos registros en el que la columna “Country” sea “United Arab Emirates”.
3. Conversión de CSV a JSON 😉
Después de haber visto algunos ejemplos de como funciona Miller, vamos a realizar la conversión de CSV a JSON que es el objetivo principal de este post :) .
Para realizar esta conversión, es tan simple como ejecutar el comando con los siguientes parámetros:
mlr --icsv --ojson cat customers-100.csv
La salida de este comando nos convierte a formato JSON todo el contenido del archivo CSV:
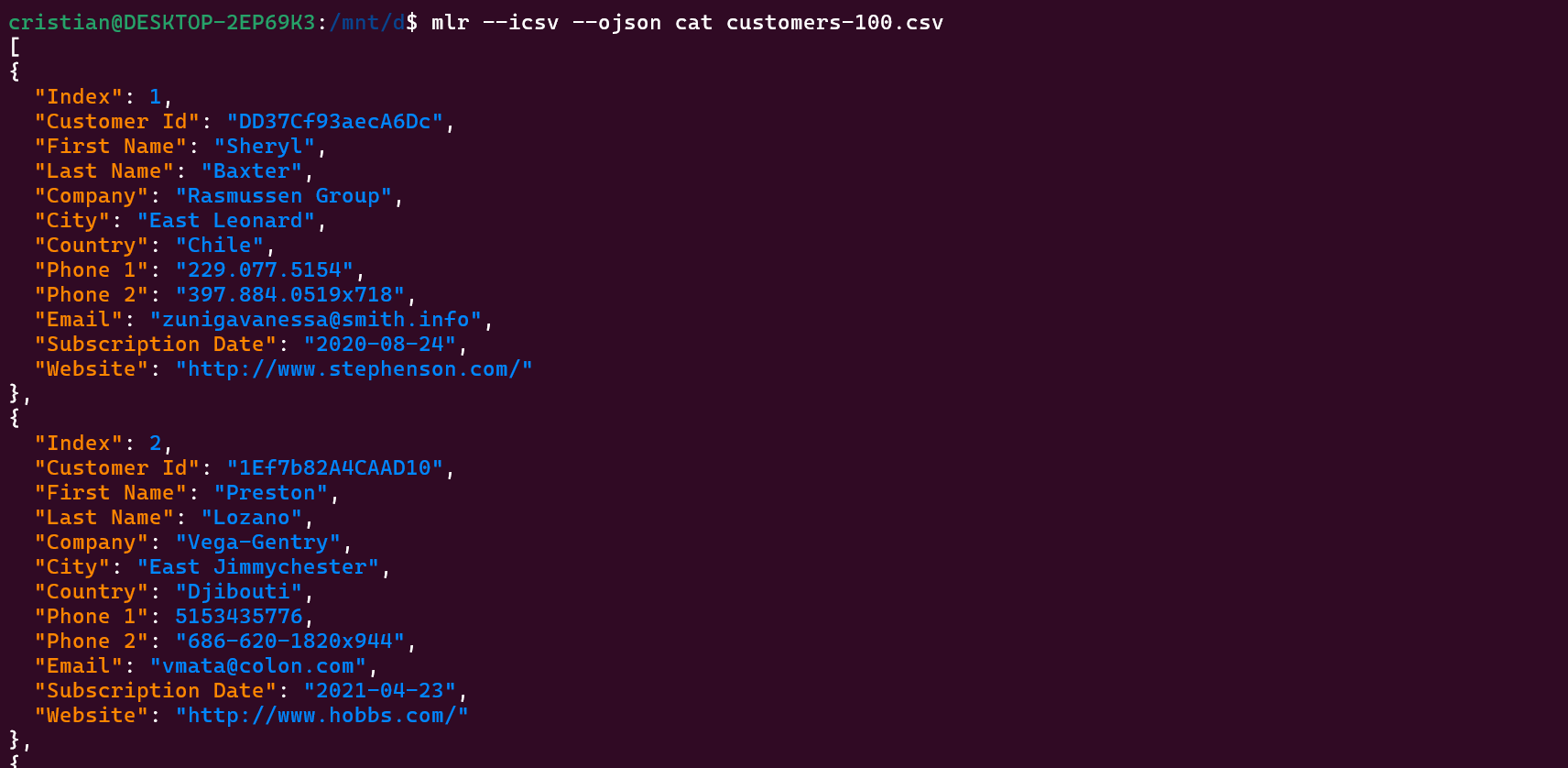
Si queremos que la salida vaya directamente a un archivo, lo único que debemos hacer es enviar la salida a través de una redirección a un archivo usando el pipe >:
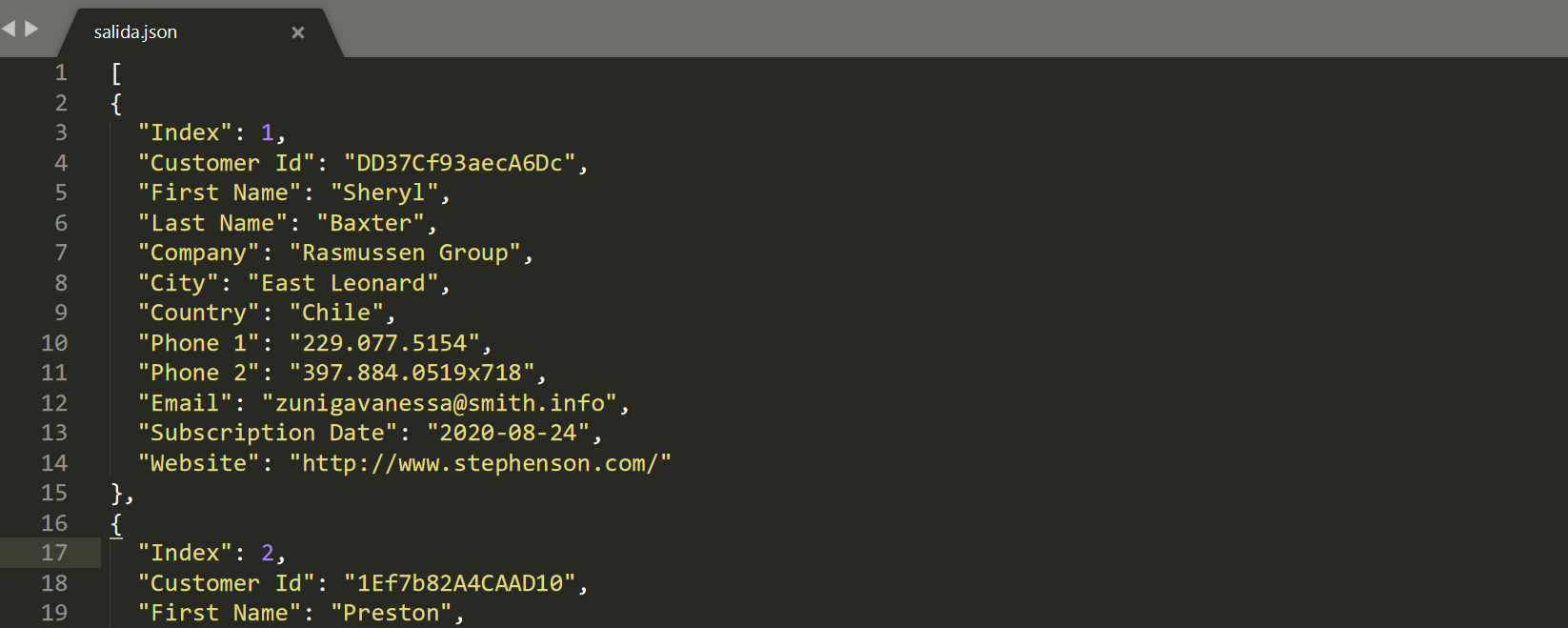
mlr --icsv --ojson cat customers-100.csv > salida.json
De esta forma tenemos el resultado de la conversión dentro de un archivo llamado salida.json
Conclusión
En este pequeño artículo hemos podido ver la potencia de Miller (mlr) para la manipulación de datos desde la línea de comandos y lo útil que es para realizar funciones de conversión de datos entre formatos, como por ejemplo, de CSV a JSON.
Dejo una serie de artículos y vídeos para ampliar el conocimiento sobre la herramienta.
Enlaces y vídeos de interés
Artículos
Vídeos
Posts que te pueden interesar:
- #2 - Los mejores enlaces sobre programación y ciencia de datos de la semana (24-04-2024)
- La mejor cheatsheet de Python
- Uso del módulo itertools en Python
- Cosas increíbles que se pueden hacer con HTMX
- #1 - Los mejores enlaces sobre programación y ciencia de datos de la semana (14-04-2024)